数据分析 009-MatPlotlib 进阶
相关模块安装:
1 | pip install scikit-learn seaborn |
模块导入
1 | import matplotlib.pyplot as plt |
matplotilib 绘图:
条形图:bar() 的用法
柱状图是用来对数据进行对比
语法:plt.bar(left, height, width=0.8, bottom=None, **kwargs)
参数说明
- left:为分类数量一致的数值序列,序列里的数值数量决定了柱子的个数,数值大小决定了距离 0 点的位置
- height:为分类变量的数值大小,决定了柱子的高度;
- width:决定了柱子的宽度,仅代表形状宽度而已;
- bottom:决定了柱子距离 x 轴的高度,默认为 None ,即表示与 x 轴距离为 0;
垂直条形图
源数据:
1 | CITY = ['北京', '上海', '天津', '重庆'] |
绘图:
1 | # 在 ubuntu 上显示中文字体 |
图如下: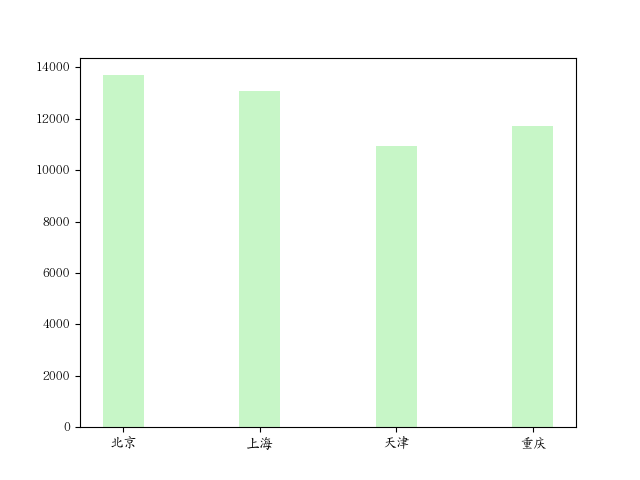
缩小 y 轴范围
源数据:
1 | CITY = ['北京', '上海', '天津', '重庆'] |
绘图:
1 | plt.bar(CITY,GDP, width=0.3, alpha=0.5, color='lightgreen') |
图如下: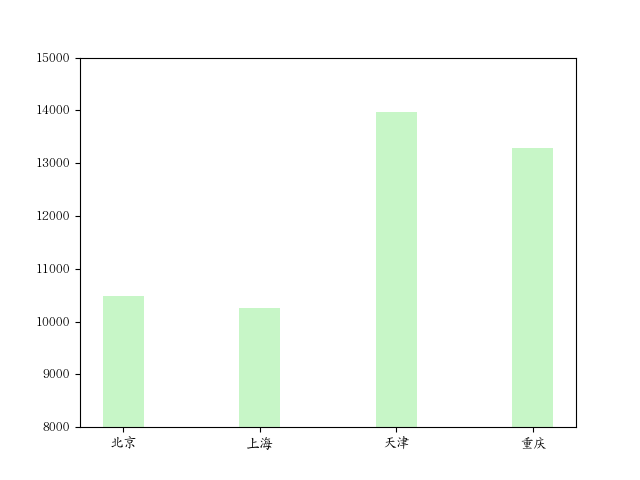
打标签
源数据:
1 | CITY = ['北京', '上海', '天津', '重庆'] |
绘图:
1 | plt.bar(CITY,GDP, width=0.3, alpha=0.5, color='lightgreen') |
图如下: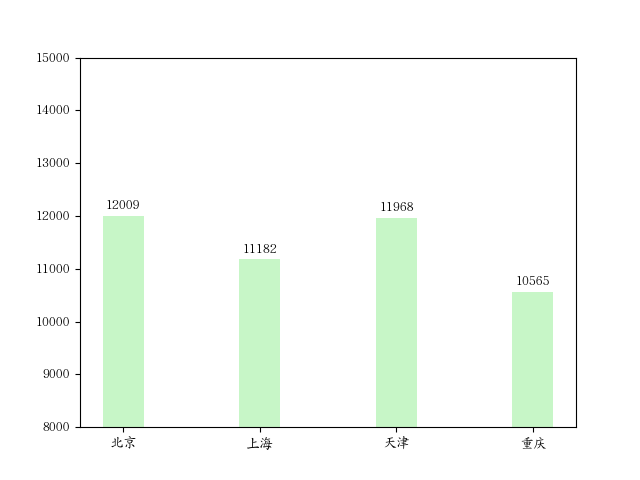
水平条形图
语法:plt.barh(x,y, left, height, width)
参数说明
- width:表示柱状图的高度,取值在 0~1 之间,默认为 0.8;
- 其它参数与 plt.bar() 类似;
源数据:
1 | label = ['亚马逊', '当当网', '中国图书网', '京东网', '天猫'] |
绘图:
1 | plt.figure(figsize=(16,9), dpi=140) |
图如下: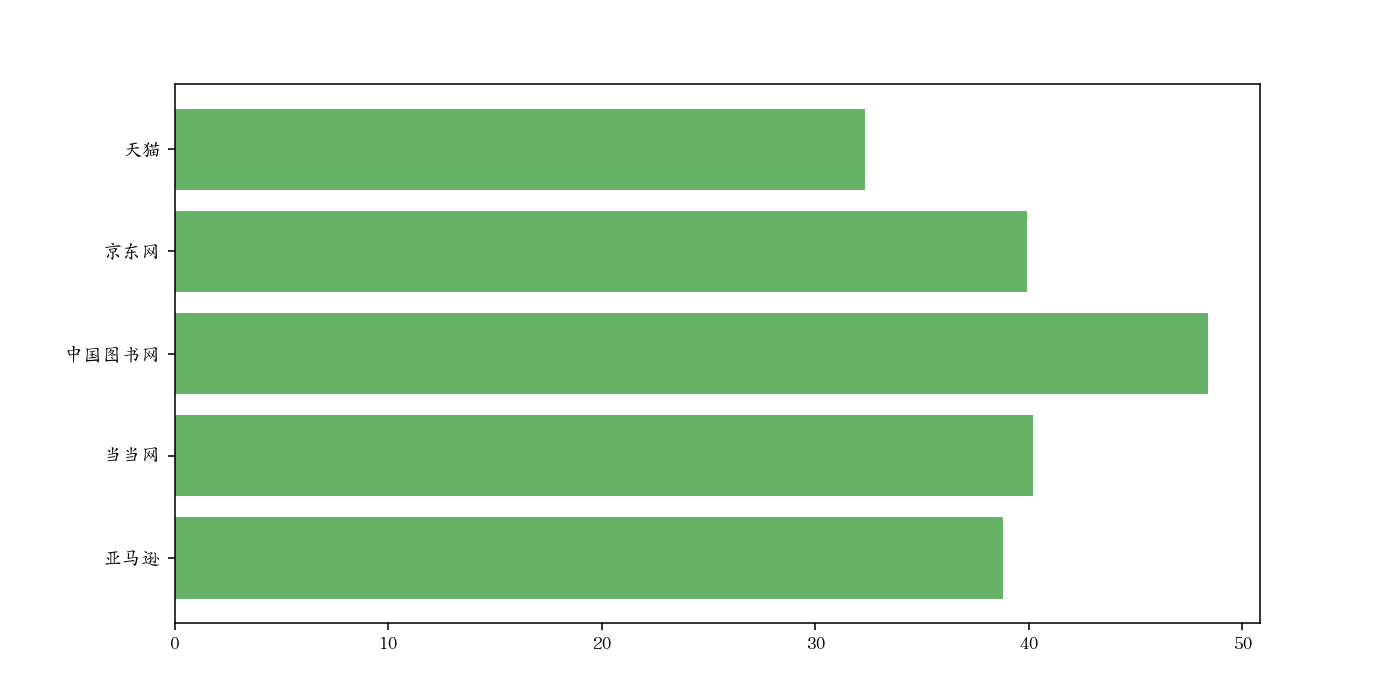
打标签
源数据:
1 | label = ['亚马逊', '当当网', '中国图书网', '京东网', '天猫'] |
绘图:
1 | plt.figure(figsize=(16,9), dpi=140) |
图如下: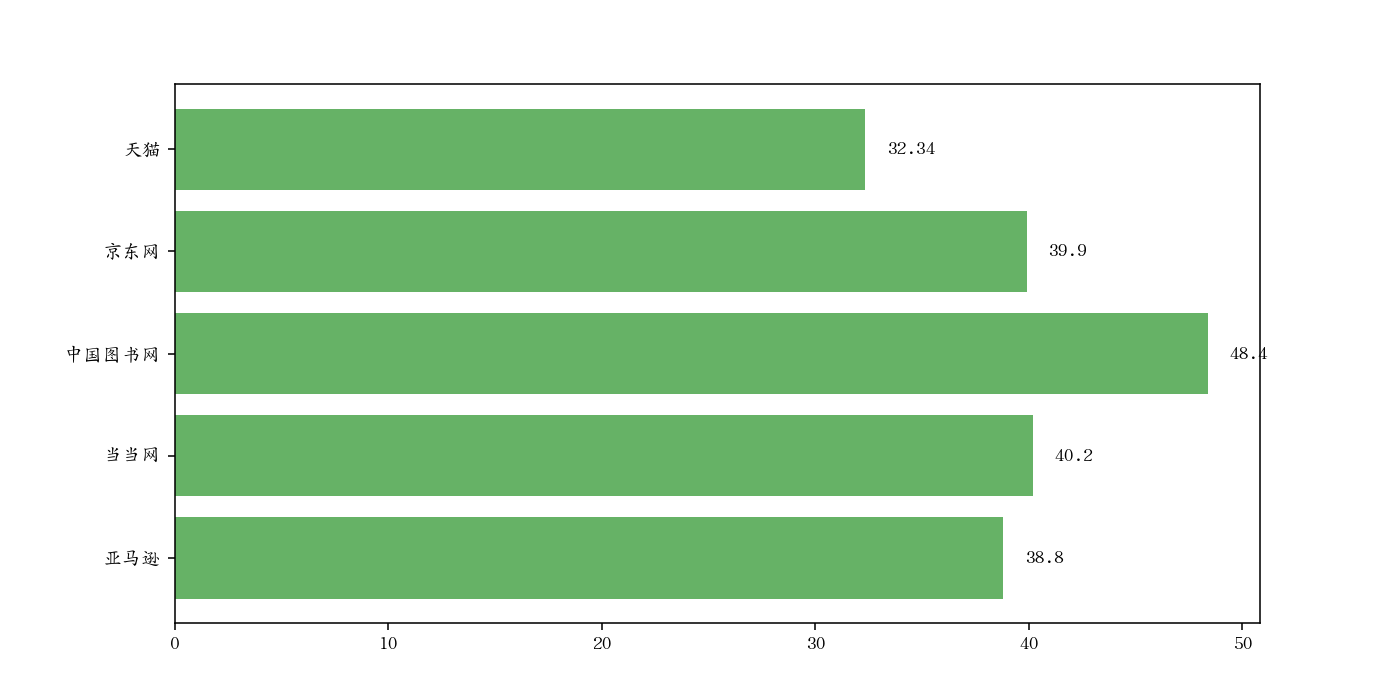
直方图:plt.hist()
直方图主要是显示各组数据数量分布的情况;用于观察一场或孤立数据
语法:plt.hist(x,bins, range, density, cumulative)
源数据:
1 | data = [random.randint(1, 200) for i in range(70)] |
绘图:
1 | plt.figure(figsize=(10, 5)) |
图如下: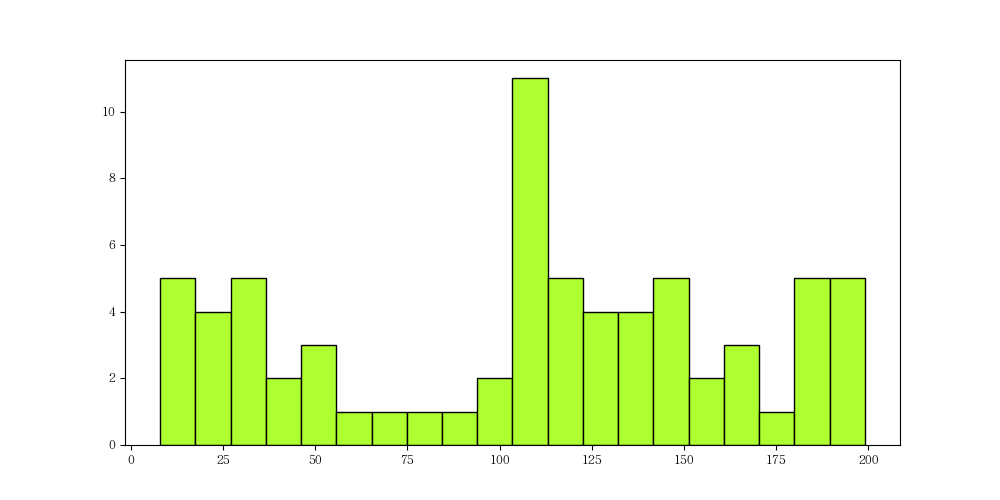
散点图:scatter() 的用法
散点图主要是用来查看数据的分布情况
源数据:
1 | height = [120, 161, 170, 182, 175, 173, 165, 155, 150, 110] |
绘图:
1 | sizes = [i*10 for i in weight] |
图如下: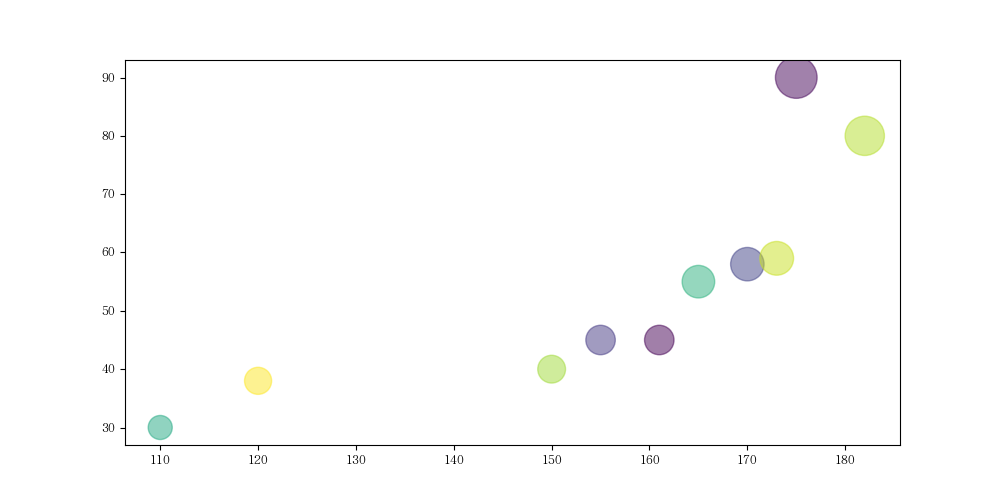
饼图:pie() 的用法
饼图主要是用来查看各数据在整体里的占比情况
源数据:
1 | label = ['中专', '大专', '本科', '硕士', '其它'] |
绘图:
1 | # 设置画布大小 |
图如下: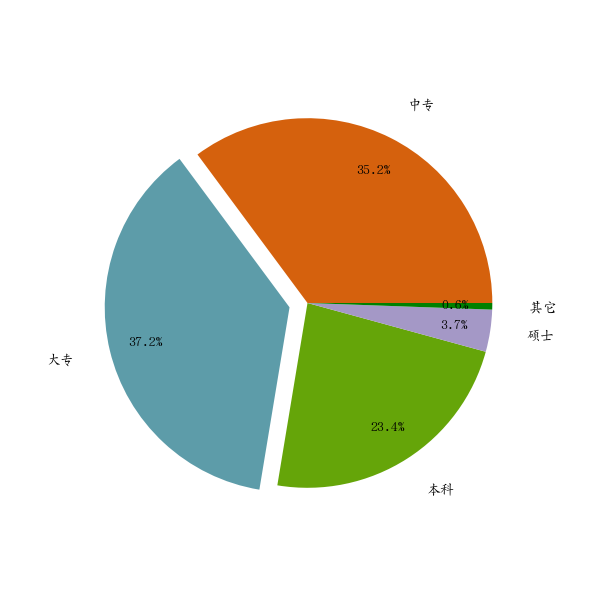
pandas 绘制图形
折线图:单数据
源数据:
1 | s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10)) |
绘图:
1 | # 设置画布大小: |
图如下: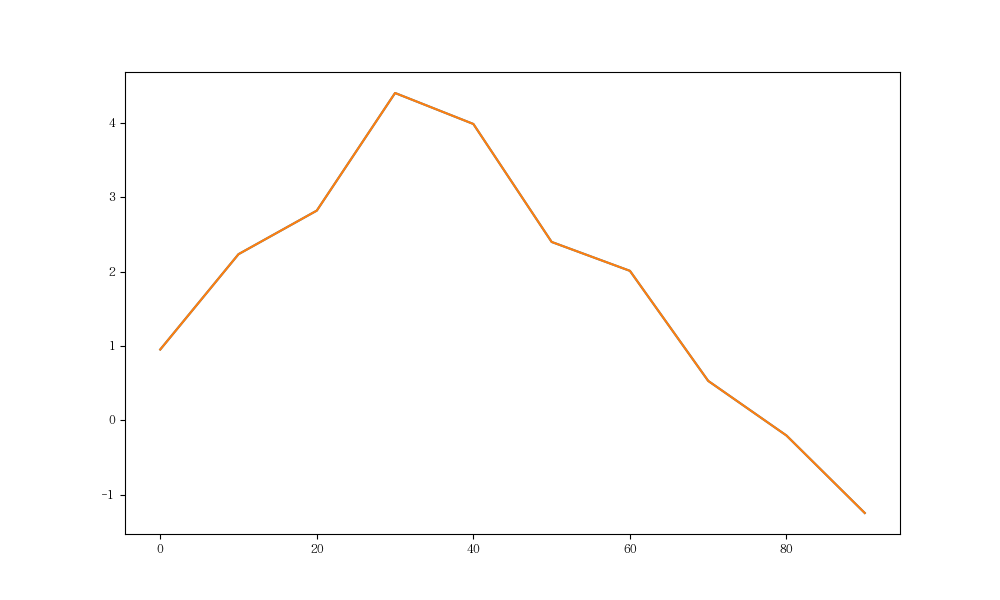
折线图:多个数据
源数据:
1 | df = pd.DataFrame(np.random.randn(10,4).cumsum(0), |
绘图:
1 | df.plot() |
图如下: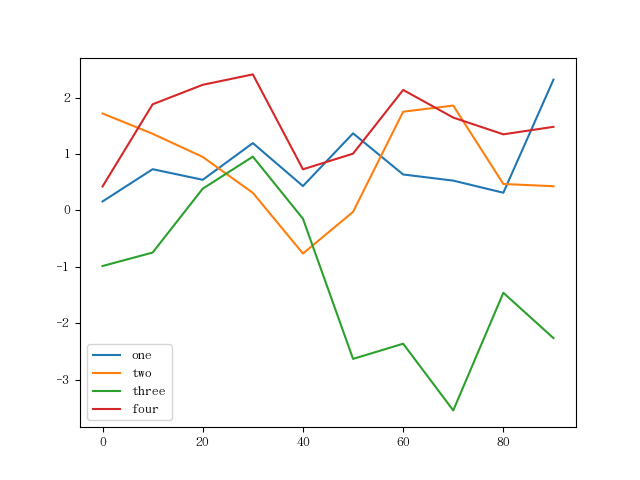
seaborn
官方网址:https://seaborn.pydata.org/
saeborn 简介
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,专注于统计数据可视化。它提供了一些高级的绘图功能和美观的默认样式,使得创建各种类型的统计图表变得更加简单和直观。
Seaborn 的设计目标是帮助用户快速地探索和理解数据,尤其是在数据分析和机器学习任务中。它提供了许多内置的函数和方法,可以轻松地创建常见的统计图表,如条形图、箱线图、散点图、热力图等。
Seaborn 还支持对数据进行分组和聚合,以便更好地展示数据之间的关系。它提供了强大的功能,如分类数据的分布可视化、多变量数据的矩阵图、数据的线性关系可视化等。
除了具有丰富的绘图功能,Seaborn 还提供了一些用于美化和定制图表的选项。您可以设置图表的主题、颜色、样式等,以及添加标签、标题、图例等元素,以增强图表的可读性和吸引力。
Seaborn 还与 Pandas 和 NumPy 等其他常用的数据处理库无缝集成,使得在数据分析过程中可以更加方便地使用。
总之,Seaborn 是一个功能强大且易于使用的统计数据可视化库。它提供了丰富的绘图选项和美观的默认样式,使得数据的探索和分析变得更加直观和有趣。无论是初学者还是专业用户,都可以通过 Seaborn 创建出令人印象深刻的统计图表。
seaborn 安装
1 | pip install seaborn |
seaborn 使用
散点图:
源数据:
1 | iris = pd.read_csv(f'/data/gitlab/python3-data-analysis/012-20231102-matplotilib 进阶及 Seaborn/iris.csv') # 该数据存放在 gitlab 数据分析仓库对应目录 |
绘图:
1 | # 设置画布大小: |
图如下: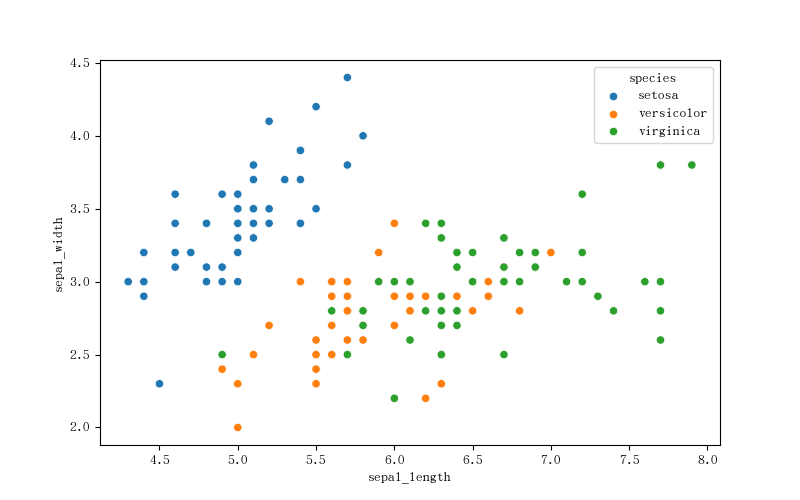
箱线图
源数据:
1 | iris = pd.read_csv(f'/data/gitlab/python3-data-analysis/012-20231102-matplotilib 进阶及 Seaborn/iris.csv') # 该数据存放在 gitlab 数据分析仓库对应目录 |
绘图:
1 | # 设置画布大小: |
图如下: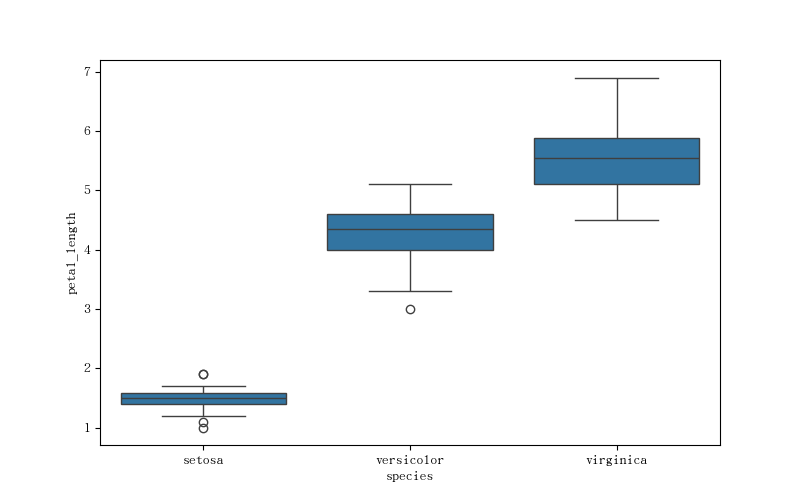
直方图
源数据:
1 | iris = pd.read_csv(f'/data/gitlab/python3-data-analysis/012-20231102-matplotilib 进阶及 Seaborn/iris.csv') # 该数据存放在 gitlab 数据分析仓库对应目录 |
绘图:
1 | # 设置画布大小: |
图如下: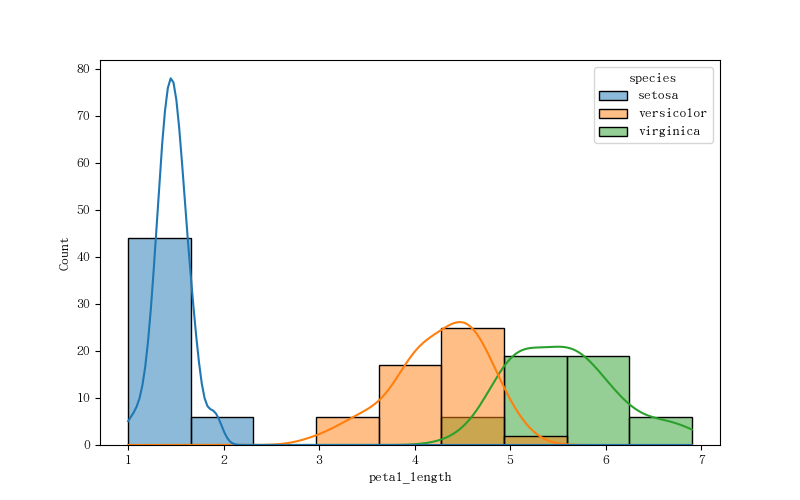
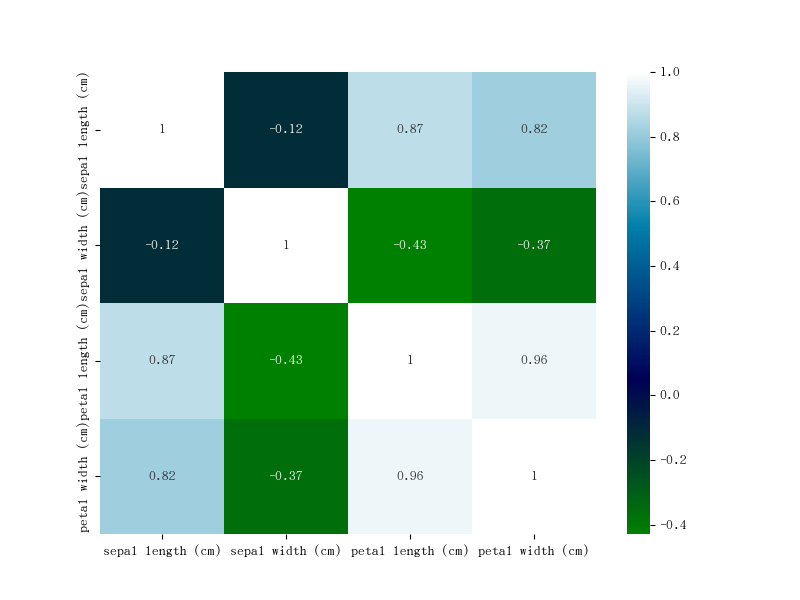
热力图
源数据:
1 | iris = pd.read_csv(f'/data/gitlab/python3-data-analysis/012-20231102-matplotilib 进阶及 Seaborn/iris.csv') # 该数据存放在 gitlab 数据分析仓库对应目录 |
绘图:
1 | ''' |
图如下: